Seeing the Unseen
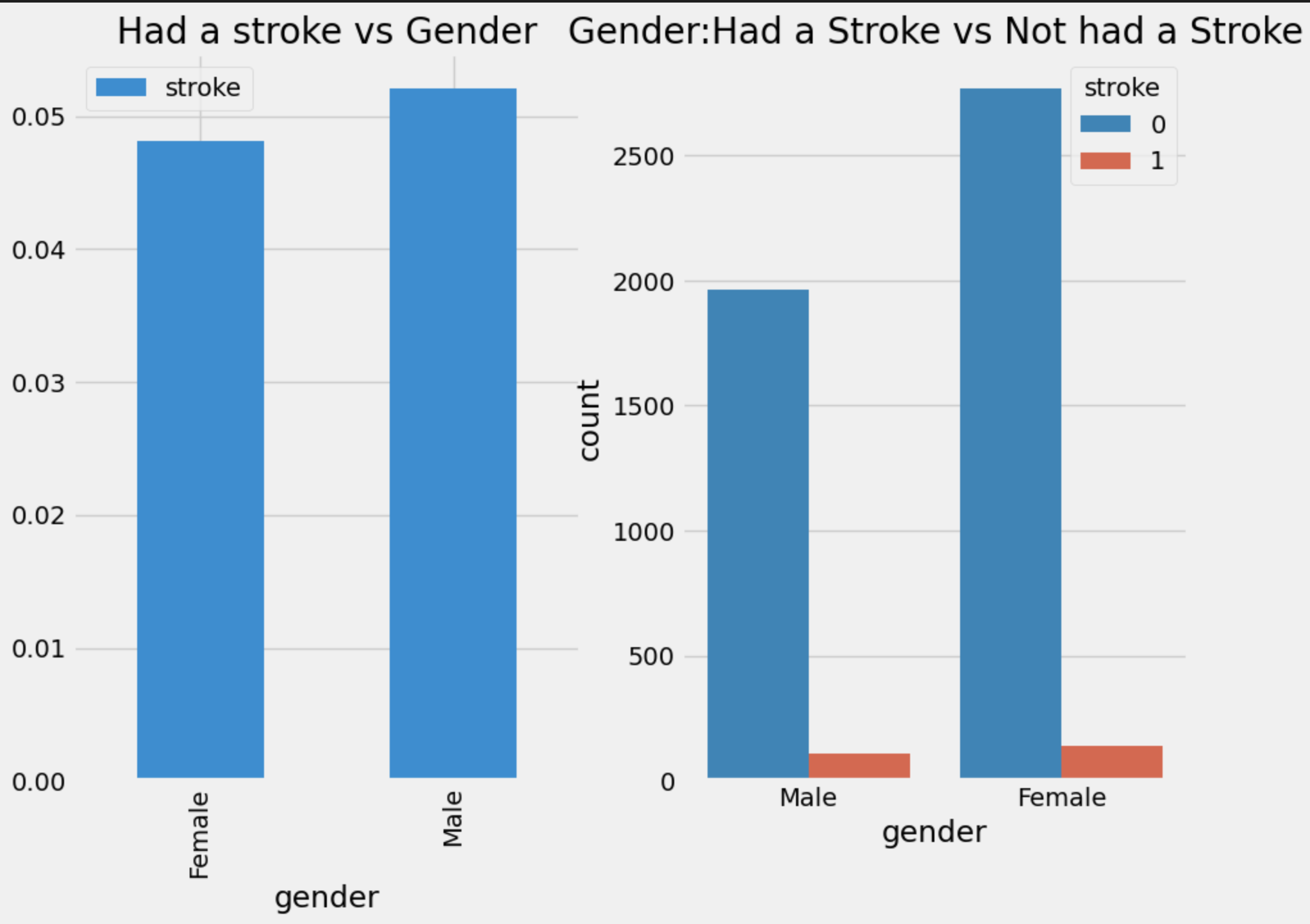
Gender
Smoking Status and Age relation
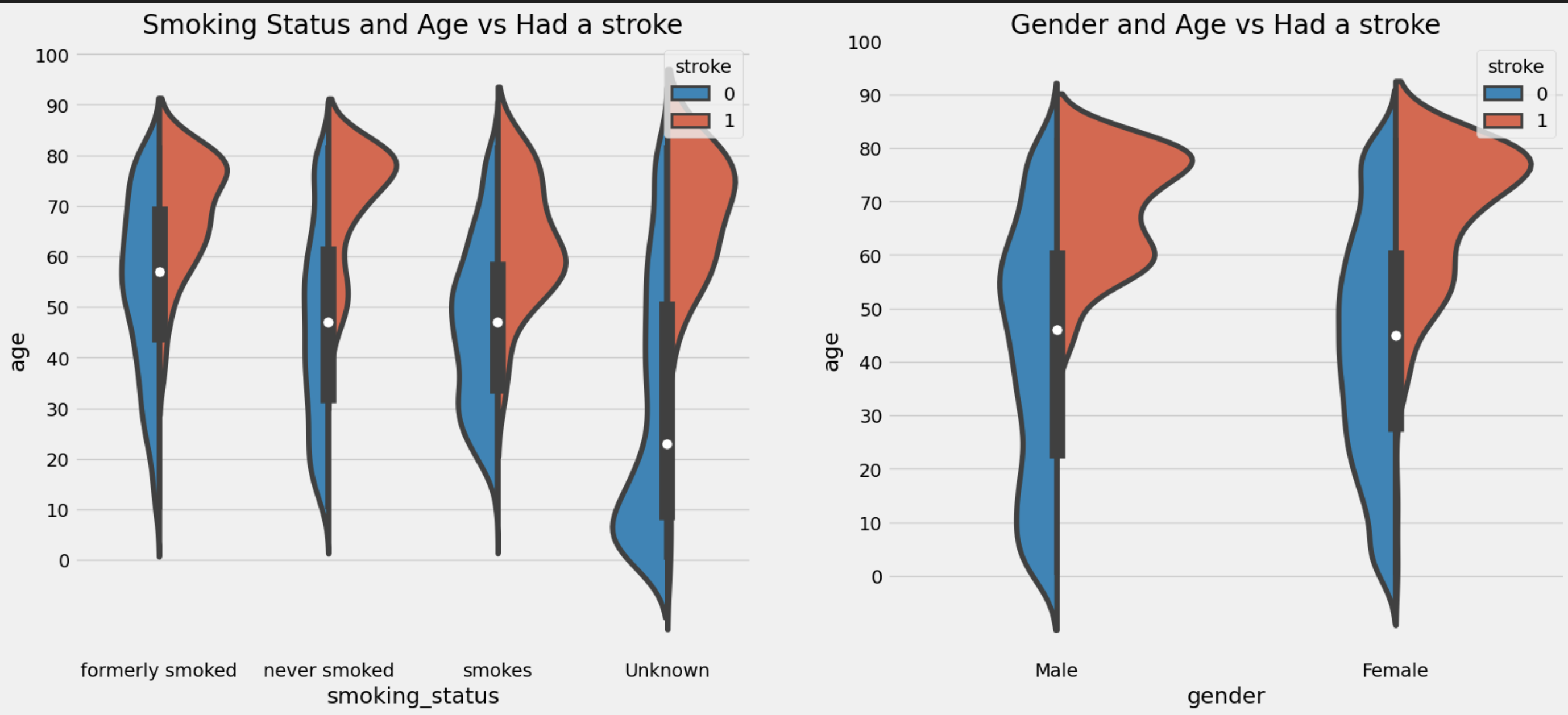
Age vs Glucose

Heart Disease and Strokes

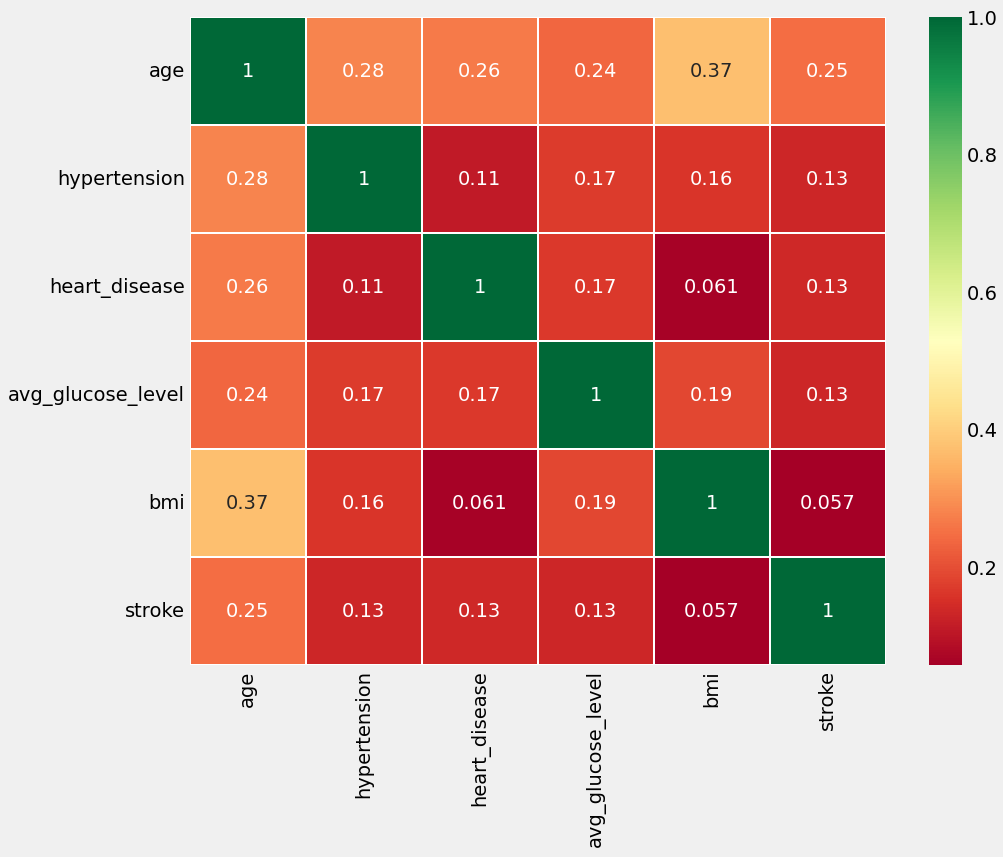
Correlation Heat Map
- This heatmap is useful for identifying potential patterns and relationships between different numeric variables in the dataset.
Model Accuracy Results
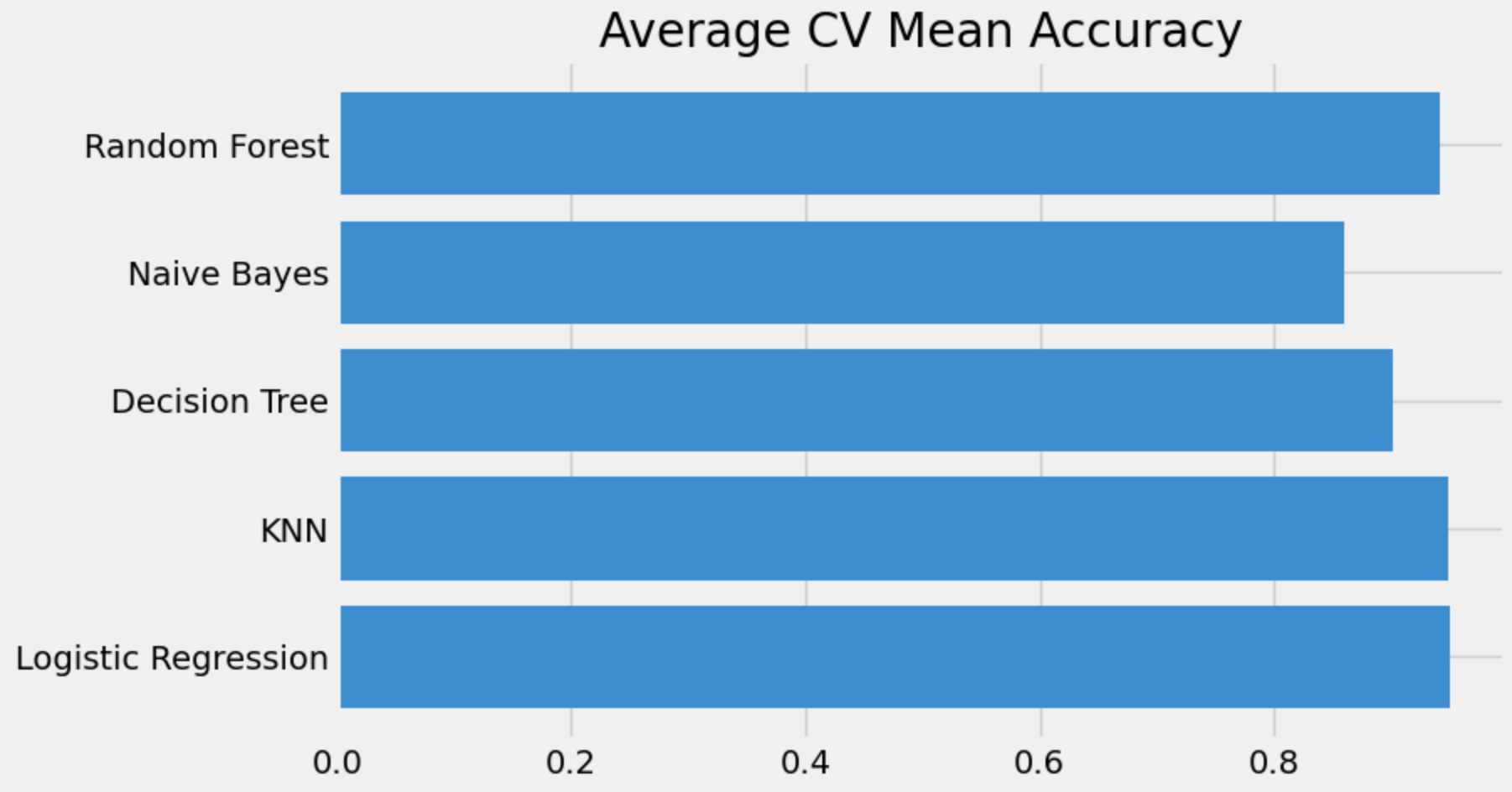
Selected Model:
Logistic Regression
- Accuracy - 95%

THANK YOU