Tweet Analytics for Disaster and Calamity Management
INFO 523 - Fall 2023 - Project Final
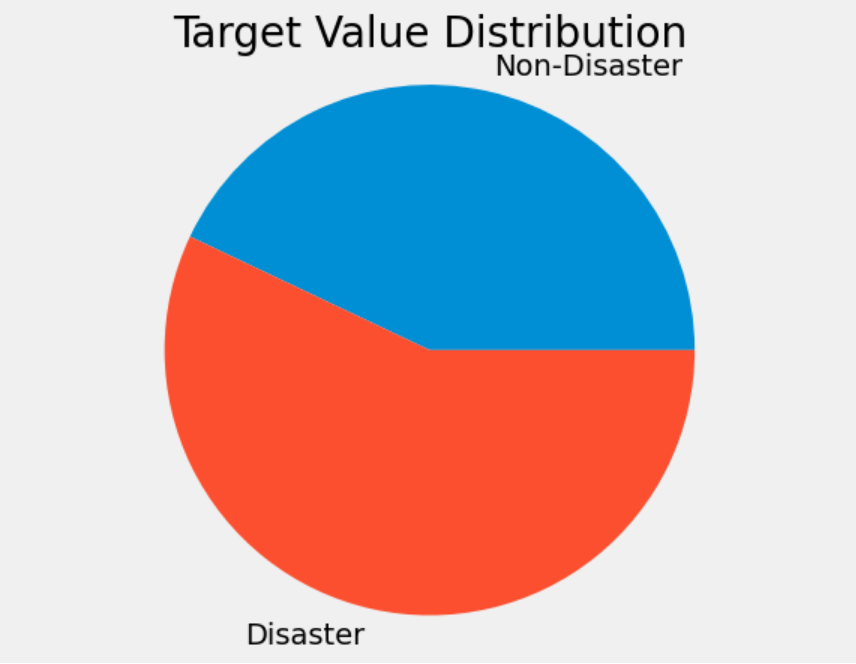
Pie Chart:
This is the target variable distribution of training dataset. With a fairly even distribution, our model had a high chance of reliable training outcomes.
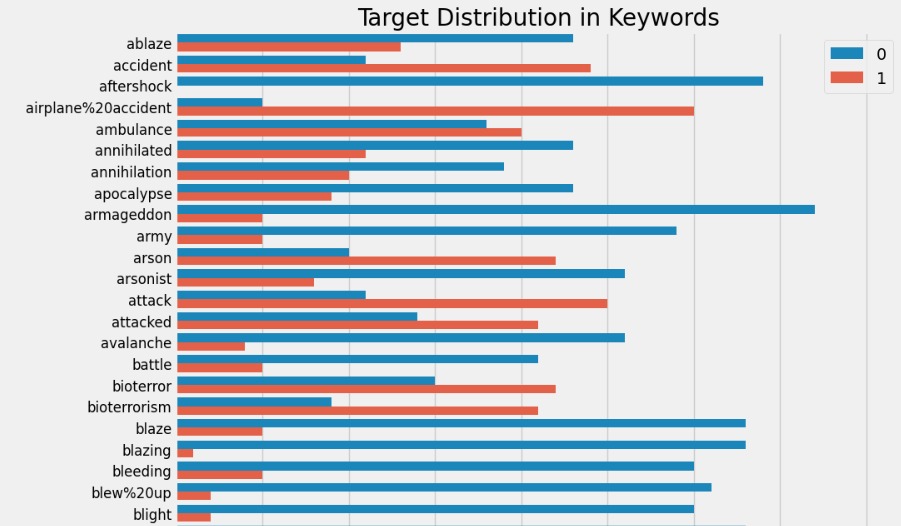
Bar Plot:
The main unique keywords that fall under the tweets tagged as “disaster tweets” has the following distribution. It is evident that tweets that talk about the disaster have really focuses terms according to the disaster.
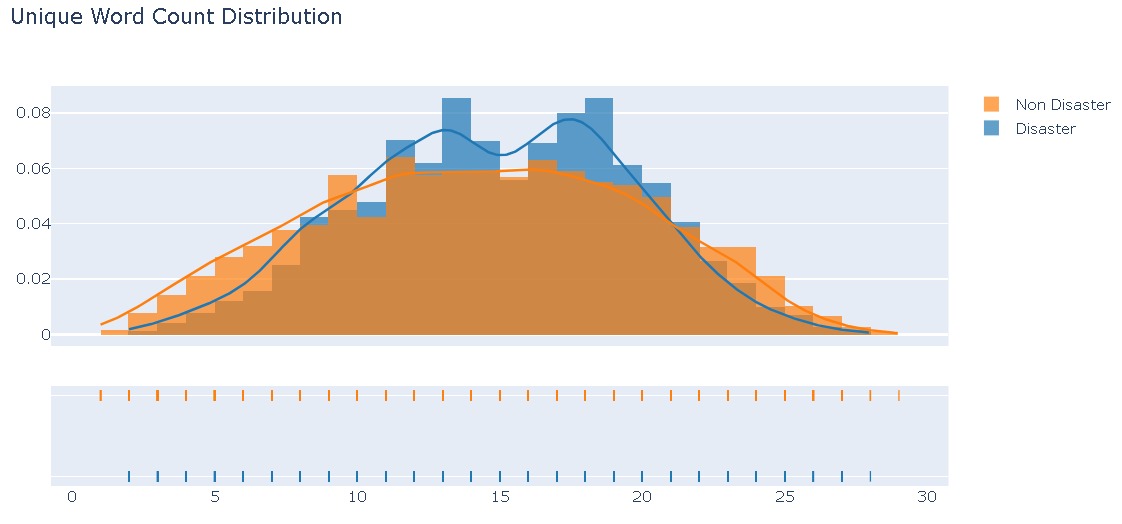
Density Plot:
With both distribution of the categories not being significantly different from an ideal normal distribution, we had the notion that the model will receive sufficient learning tokens
Word Cloud:
This is the wordcloud from the combined tweets of the dataset, for the “disaster” class.

Results:
hash_earthquake:

Results:
hash_flood:
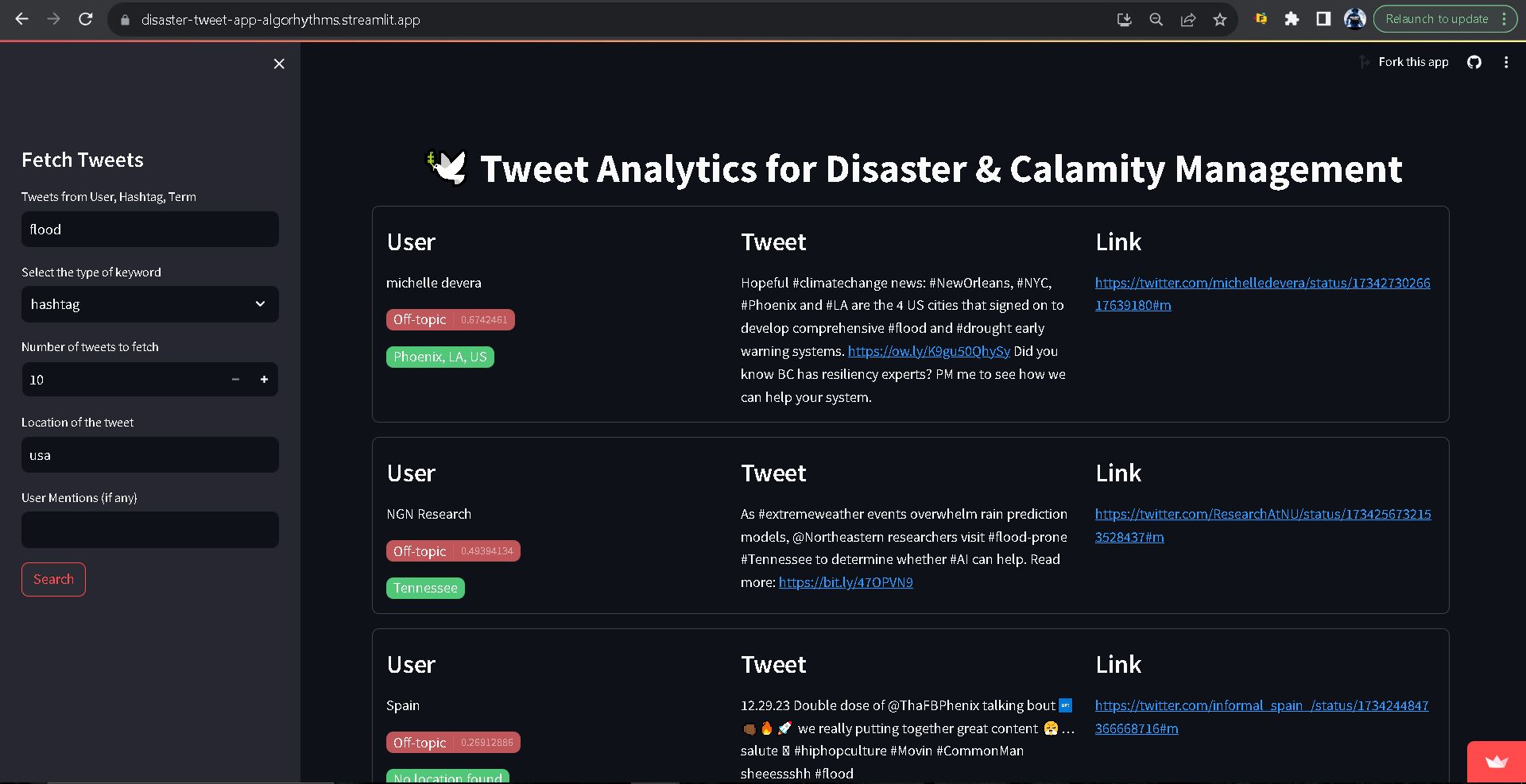
Results:
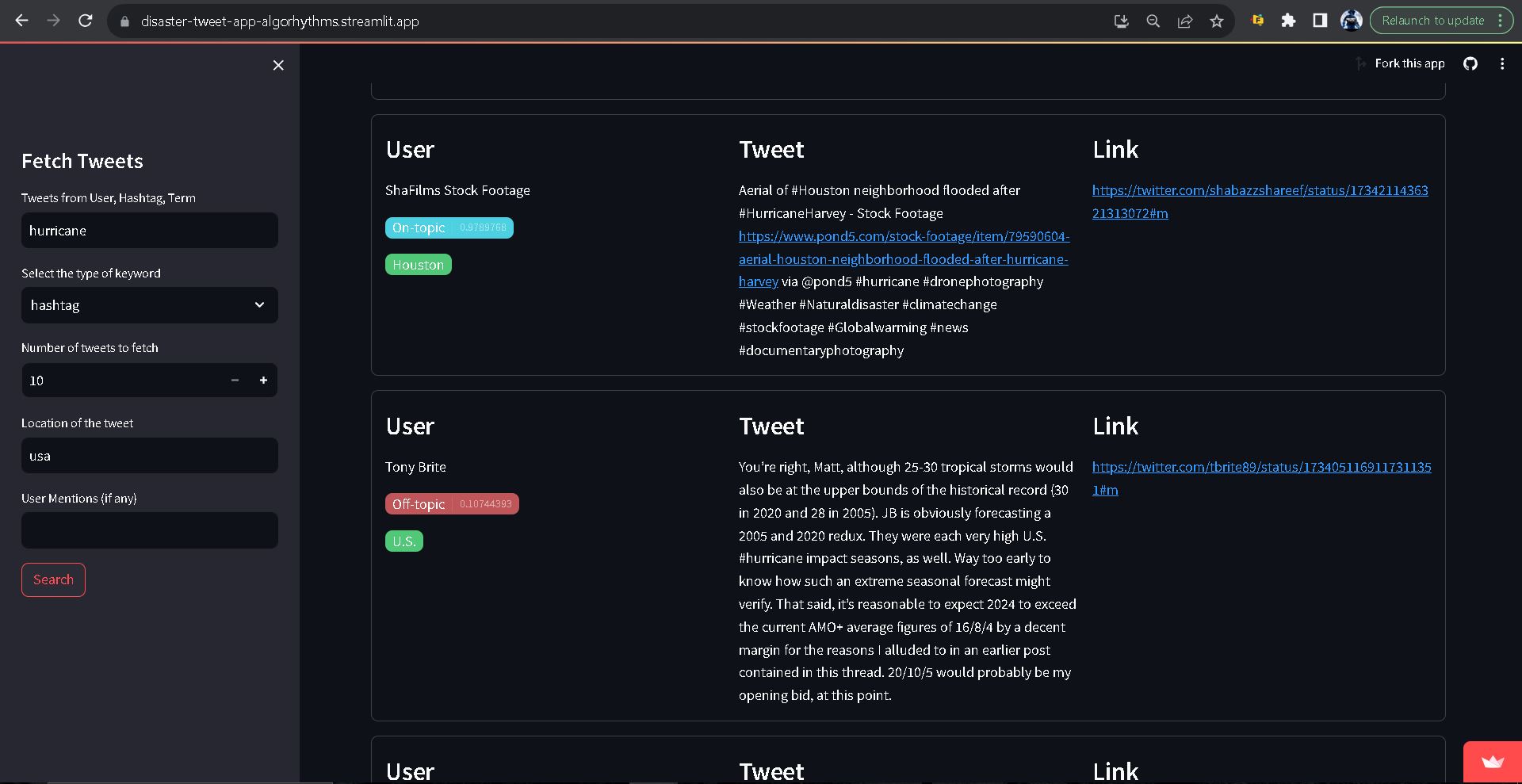
hash_hurricane:
Conclusion:
It has been a constant effort of the developer community to utilize twitter and generate analysis to manage/monitor disasters. However, there are some challenges when considering social media as an information source for disaster response. In particular, social media streams contain large amounts of irrelevant messages such as rumors, advertisements, or even misinformation.
This project is an improvement to previously attempted disaster tweet monitoring systems hosted by Google (Tensorflow and Kaggle competitions). What we achieved on top of the previous attempts, is the improved model scores and higher analytic insights on the location tracking.
This particular attempt can serve as a derivation for improve intelligence received during a crisis, and can enable intelligent officers to access calls for help quickly.