🕊️ Tweet Analytics for Disaster & Calamity Management
INFO 523 - Project Final
Abstract
Embracing the evolving landscape of disaster management, our project, Tweet Analytics for Disaster & Calamity Management, endeavors to curate critical and dependable insights as a beacon for those affected. Central to our endeavor is the differentiation between authentic and misleading tweets concerning calamities such as forest fires, earthquakes, and floods. Leveraging binary classification models and cutting-edge algorithms, we meticulously scrutinize live data streams, culminating in a comprehensive GUI that delivers actionable intelligence. Our mission is dedicated to furnishing trustworthy, real-time information to enhance the efficiency and efficacy of disaster response and management protocols.
Introduction
Amidst the ever-evolving landscape of disasters, effective and prompt management necessitates innovative solutions leveraging the dynamic realm of social media. Our project stands at the forefront, addressing the challenges inherent in conventional crisis information gathering by harnessing the power of Twitter as a vital source of real-time data. With a proactive stance, we delve into tweet classification, employing techniques like tokenization to distill keywords related to disasters and non-disaster content, coupled with advanced models such as BERT and LSTM. Through data extraction from crucial topics like forest fires and earthquakes via Tweepy, our aim is to enrich a resilient disaster management strategy. The imminent integration of a user-friendly GUI interface will play a pivotal role in disseminating our predictions and outputs, culminating in a comprehensive and accessible tool for emergency responders and disaster management professionals.
Approach
Exploration of the Data
Our analysis plan involved exploring the dataset for suitability of the training. The insights are shown here
This is the target variable distribution of training dataset. With a fairly even distribution, our model had a high chance of reliable training outcomes.
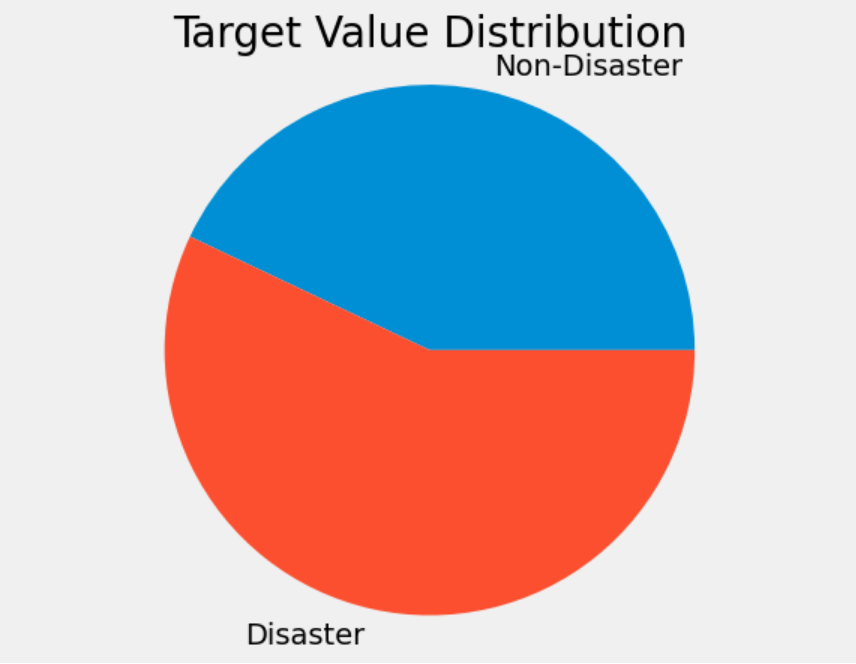
This is the target variable distribution of training dataset. With a fairly even distribution, our model had a high chance of reliable training outcomes.
This is the wordcloud from the combined tweets of the dataset, for the “disaster” class.

Fake Tweet Classification
Our approach involved a comprehensive classification of tweets, distinguishing between disaster-related and non-disaster-related content based on diverse metrics like keyword count, character count, and word count distributions. This meticulous analysis was instrumental in unraveling the nuances inherent in tweets during times of calamity, allowing for a more profound comprehension of their content and contextual relevance. To delve further into these insights, we constructed illuminating word clouds for both disaster and non-disaster tweets. These visual representations encapsulated the most prevalent words in each category, offering a vivid portrayal of the prevalent themes and discourse within the realm of calamitous events.
Tokenization
Tokenization is the process of breaking down text into smaller units, known as tokens. These tokens can be individual words or subwords, phrases, or even characters, depending on the specific tokenization technique used. The primary goal of tokenization is to facilitate natural language processing tasks by converting textual data into a format that can be easily handled by algorithms and models.
Utilizing the Tokenizer() function from the Keras library in Python, we meticulously tokenized our textual data with a specific vocabulary size set at 1000. The outcome of this process yielded a list of sequences, where each sequence encapsulated the transformation of textual content into a sequence of integers. This transformation paved the way for a structured and numerical representation of the textual information, laying the groundwork for subsequent analysis and modeling endeavors.
BERT Model Implementation
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a pre-trained language representation model developed by Google. It’s designed to understand the context of words in a sentence by capturing bidirectional relationships in the text.
Key features of BERT:
Bidirectional Encoding: BERT considers the full context of a word by looking at both the left and right context in all layers of the model. This bidirectional approach helps in understanding the nuances of language.
Pre-trained Model: BERT is pre-trained on large corpora of text, learning to predict missing words in a sentence, which enables it to capture intricate relationships between words.
Fine-tuning: BERT’s pre-trained weights can be fine-tuned on specific tasks by adding additional layers or training it on domain-specific data. This allows BERT to be adapted to various natural language processing (NLP) tasks like text classification, named entity recognition, question answering, and more.
Embeddings: BERT generates contextual word embeddings that capture the meaning of a word based on its context in a sentence. These embeddings are used as features for downstream NLP tasks.
We tried to implement a BERT-based binary classification model, achieving an accuracy of approximately 82% after three epochs. The BERT model is renowned for its contextual understanding and representation capabilities. Due to lack of computational resources we had to abort the model and moved ahead with a different approach.
LSTM Model Exploration
Long Short-Term Memory (LSTM) is a type of recurrent neural network (RNN) architecture designed to handle the issue of vanishing or exploding gradients in traditional RNNs. LSTMs are capable of capturing long-term dependencies in sequential data by using a memory cell that can maintain information over long sequences.
Key features of LSTM:
Memory Cells: LSTMs use memory cells to store information, which allows them to remember and access information from earlier time steps in a sequence.
Gates: LSTMs contain three gates: input gate, forget gate, and output gate. These gates regulate the flow of information into and out of the memory cell, enabling the network to learn when to forget or update information.
Long-Term Dependencies: LSTMs excel in capturing and retaining information over longer sequences, making them suitable for tasks involving sequential data like text, time series, speech, etc.
Training: LSTMs are trained using backpropagation through time (BPTT) and can be optimized using various gradient descent algorithms like Adam, RMSprop, etc.
In response to resource limitations, we explored the implementation of an LSTM (Long Short-Term Memory) model, achieving a commendable accuracy of around 80%. The LSTM model, a type of recurrent neural network, demonstrated its effectiveness in capturing sequential dependencies in the data.
Data Extraction from ntscraper
The Ntscraper library is a user-friendly tool tailored for effortless data retrieval from Nitter instances. It empowers users to extract tweets efficiently through a range of functionalities:
Search and Scraping Capabilities: Easily locate and extract tweets containing specific terms or hashtags, streamlining the process of aggregating targeted content.
User Profile Scraping: Seamlessly retrieve tweets from user profiles, enabling a focused exploration of individual user activity.
User Profile Information: Fetch pertinent profile details like the display name, username, tweet count, and profile picture, offering comprehensive insights into user profiles.
Furthermore, in the absence of a specified instance, the scraper automatically selects a random public instance, ensuring a seamless scraping experience regardless of the instance availability.
Utilizing the robust capabilities of the ntscraper API, our initiative focused on extracting critical data related to distinct disaster topics, encompassing forest fires, floods, earthquakes, and hurricanes. By harnessing this API, we accessed real-time and contextually relevant information, significantly enriching the depth and breadth of our analysis.
Geo-location Extraction
We used spacy and the geo-tagging entities of spacy nl model en_core_web_sm to identify the location of the tweets.
This strategic utilization empowered our project to stay dynamically aligned with ongoing events and swiftly gather comprehensive insights crucial for in-depth examination and effective disaster management strategies.
GUI Interface Presentation (Streamlit)
Streamlit is an open-source Python library that simplifies the process of creating web applications for data science and machine learning projects. It allows developers and data scientists to build interactive and customizable web-based applications using simple Python scripts.
Key features of Streamlit:
Easy-to-Use: Streamlit provides a straightforward and intuitive API that allows users to create web applications using familiar Python scripting.
Rapid Prototyping: With Streamlit, you can quickly create interactive dashboards, visualizations, and applications by leveraging its built-in widgets and components.
Integration: It seamlessly integrates with popular data science libraries like Pandas, Matplotlib, Plotly, and more, enabling easy incorporation of data manipulation and visualization capabilities into web apps.
Real-Time Updates: Streamlit’s reactive framework automatically updates the app in response to changes in the underlying data or user inputs, providing a dynamic and responsive user experience.
Deployment: Once the application is built, it was deployed upon Streamlit’s own cloud sharing platform.
We intend to present our predictions and outputs through an intuitive GUI (Graphical User Interface) interface. This interface will facilitate user-friendly access to our analytical insights, promoting effective decision-making in disaster and calamity management. For developing GUI we use streamlit.
Results
By analyzing the conversations and trends on Twitter during such situations, the project has uncovered patterns by validating the truthfulness of information, improve situational awareness, and ultimately contribute to the resilience and safety of individuals and communities faced with critical events. The major motivation behind the project is to save lives and improve public safety by harnessing the power of Twitter data to access real-time information, understand & validate public sentiment.
The implemented model serves as a reliable, strictly filtering classification algorithm that identifies the genuinity in the tweet text. The information of geolocation extraction further amplifies the utility of the project by only highlighting meaningful insights from the text, allowing the user to ignore irrelevant details.
The insights paired with a seamless interface which is easy to use enables calamity management and monitoring individuals to track real-time events on the social media.
Drawbacks
There were several instances where the model mislabeled the tweet, yet it wasn’t too far off in the confidence level, proving that the threshold can be adjusted to allow robust filtering.
This project requires capital allowance to a certain extent, yet it was made within the limits and capacities of the team members.
Deployment
🔗 The GUI made with the script in the disastertweetapp/ folder has been deployed on this link: (https://disaster-tweet-app-algorhythms.streamlit.app/)
GUI Screenshot

Conclusion
In summary, our project endeavors to provide a robust and comprehensive solution to the challenges posed by dynamic disasters and calamities. By using models like BERT and LSTM
It has been a constant effort of the developer community to utilize twitter and generate analysis to manage/monitor disasters. However, there are some challenges when considering social media as an information source for disaster response. In particular, social media streams contain large amounts of irrelevant messages such as rumors, advertisements, or even misinformation.
This project is an improvement to previously attempted disaster tweet monitoring systems hosted by Google (Tensorflow and Kaggle competitions). What we achieved on top of the previous attempts, is the improved model scores and higher analytic insights on the location tracking.
This particular attempt can serve as a derivation for improve intelligence received during a crisis, and can enable intelligent officers to access calls for help quickly.